本文共 3078 字,大约阅读时间需要 10 分钟。
本周主要介绍了梯度下降算法运用到大数据时的优化方法。
一、内容概要
- Gradient Descent with Large Datasets
- Stochastic Gradient Descent
- Mini-Batch Gradient Descent
- Stochastic Gradient Descent Convergence
- Advanced Topics
- Online Learning
- Map Reduce and Data Parallelism(映射化简和数据并行)
二、重点&难点
Gradient Descent with Large Datasets
1) Batch gradient descent
首先回顾一下普通梯度下降算法:,也叫批量梯度下降算法。
\[h_θ(x)=\sum_{j=1}^{n}θ_jx_j \tag {1.1}\]
\[J(θ) = \frac{1}{2m}\sum_{i=1}^{m}(h_θ(x^{(i)}) - y^{(i)})^2 \tag {1.2}\]Repeat until convergence{
\[\begin{align} θ_j & = θ_j - α\frac{∂J(θ)}{∂θ_j} \tag {1.31} \\ & = θ_j - α\frac{1}{m}\sum_{i=1}^{m}( h_θ(x^{(i)})-y^{(i)})x_j^{(i)} \quad j=1,2...,n \tag {1.32} \end{align}\] }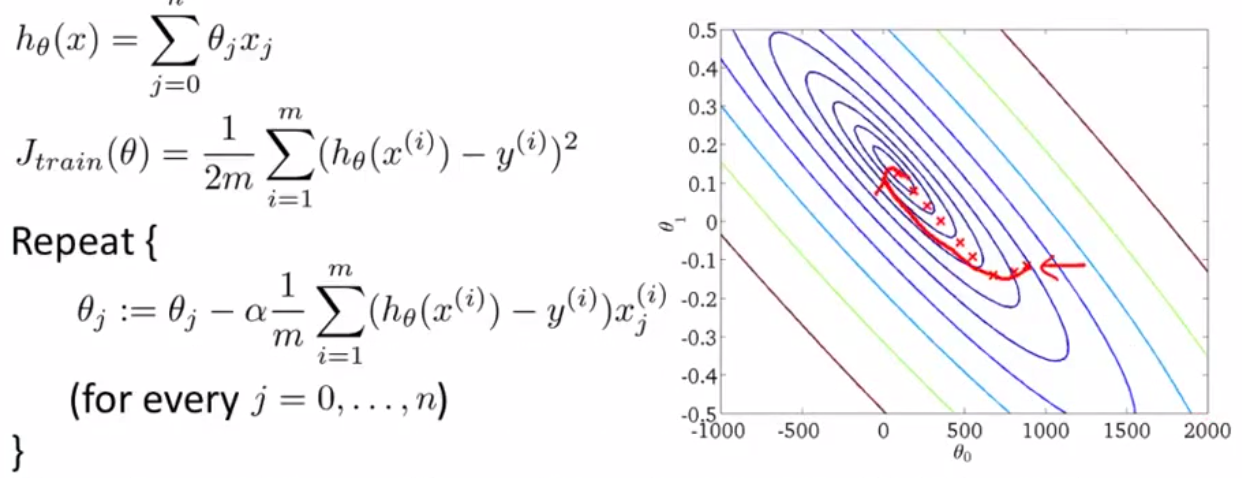
1)Stochastic Gradient Descent
将计算大数据时,即m很大的情况下,上面 (1.32) 式右边有一个 Σ(累加) 符号,每一次迭代显然会耗费大量的时间。所以提出了随机梯度下降算法进行改进。
\[ cost(θ,(x^{(i)}, y^{(i)})) = \frac{1}{2}( h_θ(x^{(i)}) - y^{(i)} )^2 \tag {2.1}\]
\[J(θ) = \frac{1}{m}\sum_{i=1}^{m}cost(θ,(x^{(i)}, y^{(i)})) \tag{2.2}\] 步骤如下:- 1.打乱数据,重新随机排列
- 2.Repeat until convergence{ \[\begin{align} θ_j &=θ_j-α\frac{∂cost(θ,(x^{(i)}, y^{(i)}))}{∂θ_j} \tag{2.31}\\ &= θ_j - α( h_θ(x^{(i)})-y^{(i)})x_j^{(i)} \quad j=1,2...,n \tag{2.32} \end{align}\] }

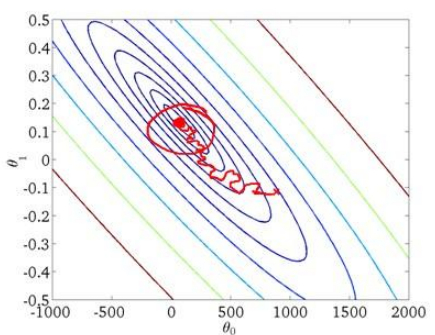
因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。
2)Mini-Batch Gradient Descent
上面的随机梯度下降的收敛过程显得比较任性,所以综合前面提到的两种梯度算法的优点提出了小批量梯度下降算法,即每次考虑一小批量的数据来更新权重,算法如下:
假设总共有m个数据,每次迭代使用b个数据进行更新
- \(i\)初始化为1
- Repeat until convergence { while(i≤m) { \(\qquad θ_j = θ_j - α\frac{1}{m}\sum_{k=i}^{i+(b-1)}( h_θ(x^{(k)})-y^{(k)})x_j^{(k)} \quad j=1,2...,n\) } i += b; }
通常我们会令 b 在 2-100 之间。这样做的好处在于,我们可以用向量化的方式来循环b 个训练实例,如果我们用的线性代数函数库比较好,能够支持平行处理,那么算法的总体表现将不受影响(与随机梯度下降相同)。
3)Stochastic Gradient Descent Convergence
本节介绍了令代价函数 J 为迭代次数的函数,绘制图表,根据图表来判断梯度下降是否收敛,并根据收敛趋势进行调试。
常见有如下四种情况:

- 左上:
- 蓝色:表示最开始的迭代情况,可以看出是收敛的,但是数据有毛刺(噪声),而且不是很光滑。
- 红色:降低学习速率α后噪音减少,是收敛效果更好
- 右上
- 蓝色:数据集为1000的时候所绘制的,可以看到本身的收敛还是不错的。
- 红色:将数据增加到5000后收敛更加平缓。(增加数据)
- 左下
- 蓝色:最开始的收敛非常糟糕,几乎不收敛
- 红色:增加数据后,开始收敛,但是收敛效果不好
- 粉色:降低α后,也几乎不收敛,所以此时可以推测是模型本身有问题,需要重新建立。
- 右下
- 模型呈现上升趋势,可能是学习速率α过大导致,可以尝试减小α。我们也可以让学习速率随着迭代次数增加而减小,如\(α=\frac{常数C_1}{迭代次数+常数C_2}\)。但是也这样有个缺陷就是你还需要不断的尝试两个参数,即两个常数,所以虽然效果可能会不错,但是调试起来会比较麻烦。
Advanced Topics
1)Online Learning
在线学习算法适用于有一系列连续的数据需要学习的情况。有点类似于随机梯度下降算法,每次使用一个数据来更新权重。比如说常用的网易云音乐,可能根据用户实时的点击、收藏等行为在线学习,从而更加符合用户时常变换的口味。
更准确的说在线学习算法指的是对数据流而非离线的静态数据集的学习。许多在线网站都有持续不断的用户流,对于每一个用户,网站希望能在不将数据存储到数据库中便顺利地进行算法学习。算法如下:
Repeat forever(直到网站倒闭233){
获取当前用户的数据(x,y) \(θ_j := θ_j - α(h_θ(x)-y)x_j \quad\)(for j in range(n))}一旦对一个数据的学习完成了,我们便可以丢弃该数据,不需要再存储它了。这种方式的好处在于,我们的算法可以很好的适应用户的倾向性,算法可以针对用户的当前行为不断地更新模型以适应该用户。
大公司会获取非常多的数据,真的没有必要来保存一个固定的数据集,取而代之的是你可以使用一个在线学习算法来连续的学习,从这些用户不断产生的数据中来学习。这就是在线学习机制,然后就像我们所看到的,我们所使用的这个算法与随机梯度下降算法非常类似,唯一的区别的是,我们不会使用一个固定的数据集,我们会做的是获取一个用户样本,从那个样本中学习,然后丢弃那个样本并继续下去,而且如果你对某一种应用有一个连续的数据流,这样的算法可能会非常值得考虑。当然,在线学习的一个优点就是,如果你有一个变化的用户群,又或者你在尝试预测的事情,在缓慢变化,就像你的用户的品味在缓慢变化,这个在线学习算法,可以慢慢地调试你所学习到的假设,将其调节更新到最新的用户行为。
2)Map Reduce and Data Parallelism(映射化简和数据并行)
这节课的内容应该可以理解成分布式计算,即把一个计算任务分配给若干个计算机(或者若干个CPU)进行计算,最后将结果汇总在一起计算,这样就可以提高计算速度。以上就是映射简化(map reduce)

MARSGGBO原创 2017-8-15
转载地址:http://ukdxx.baihongyu.com/